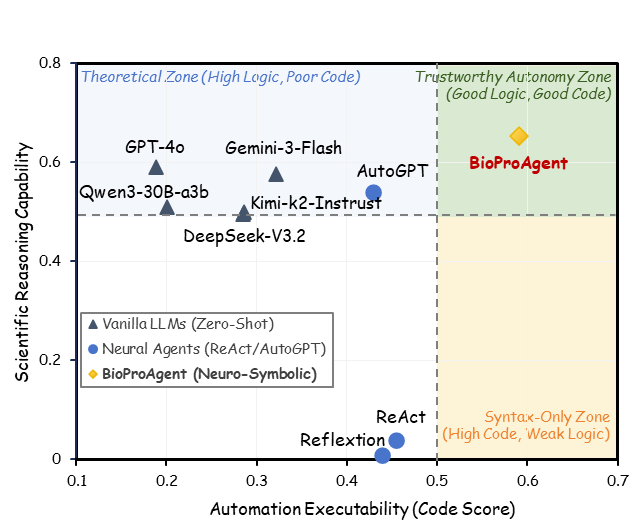
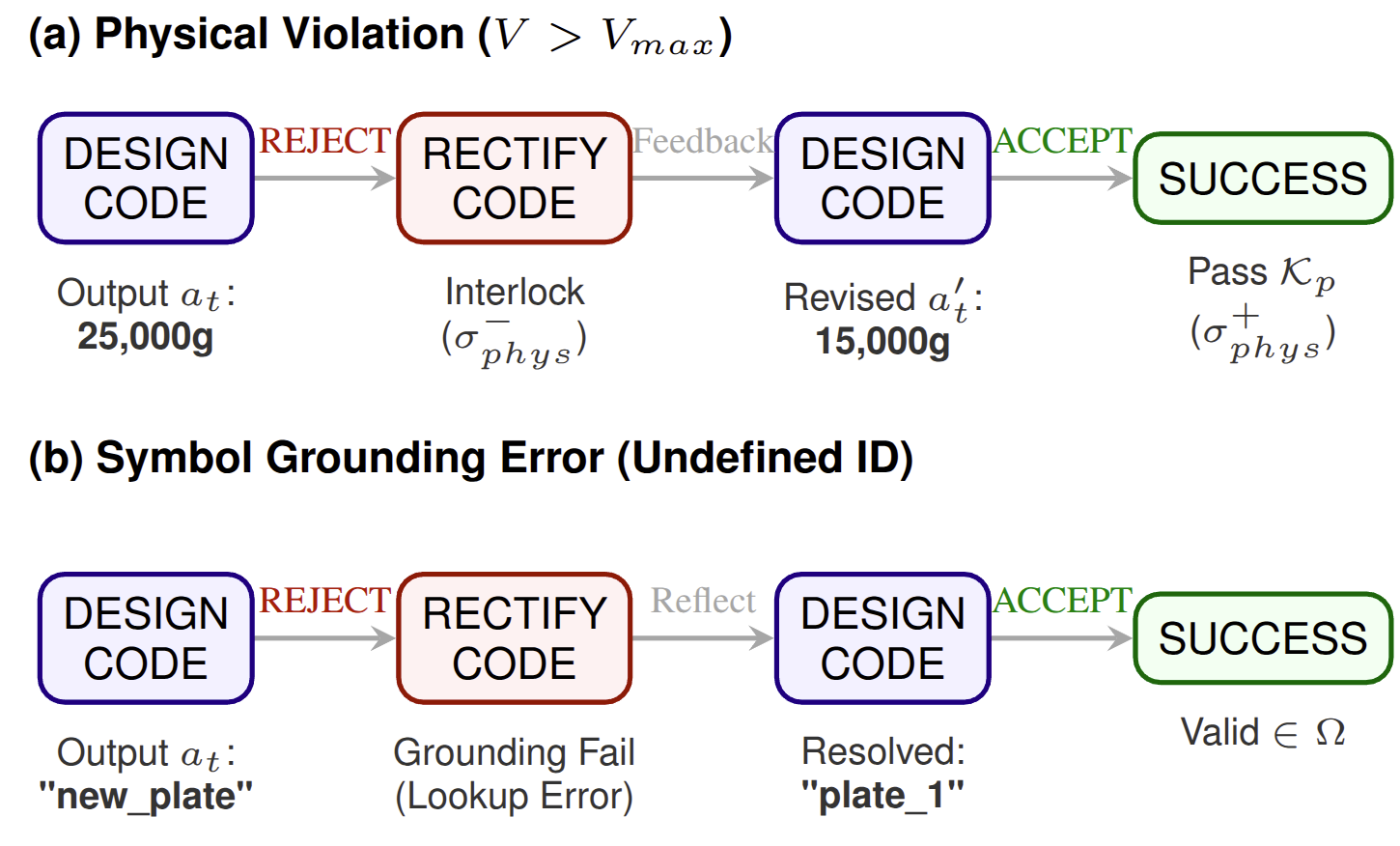
🧬 数据集:BioProBench
我们提出 BioProBench,这是首个面向生物实验流程程序化推理的大规模资源, 包含近 27,000 份 protocol 与超过 550,000 条结构化样本, 覆盖生物学多个子领域。
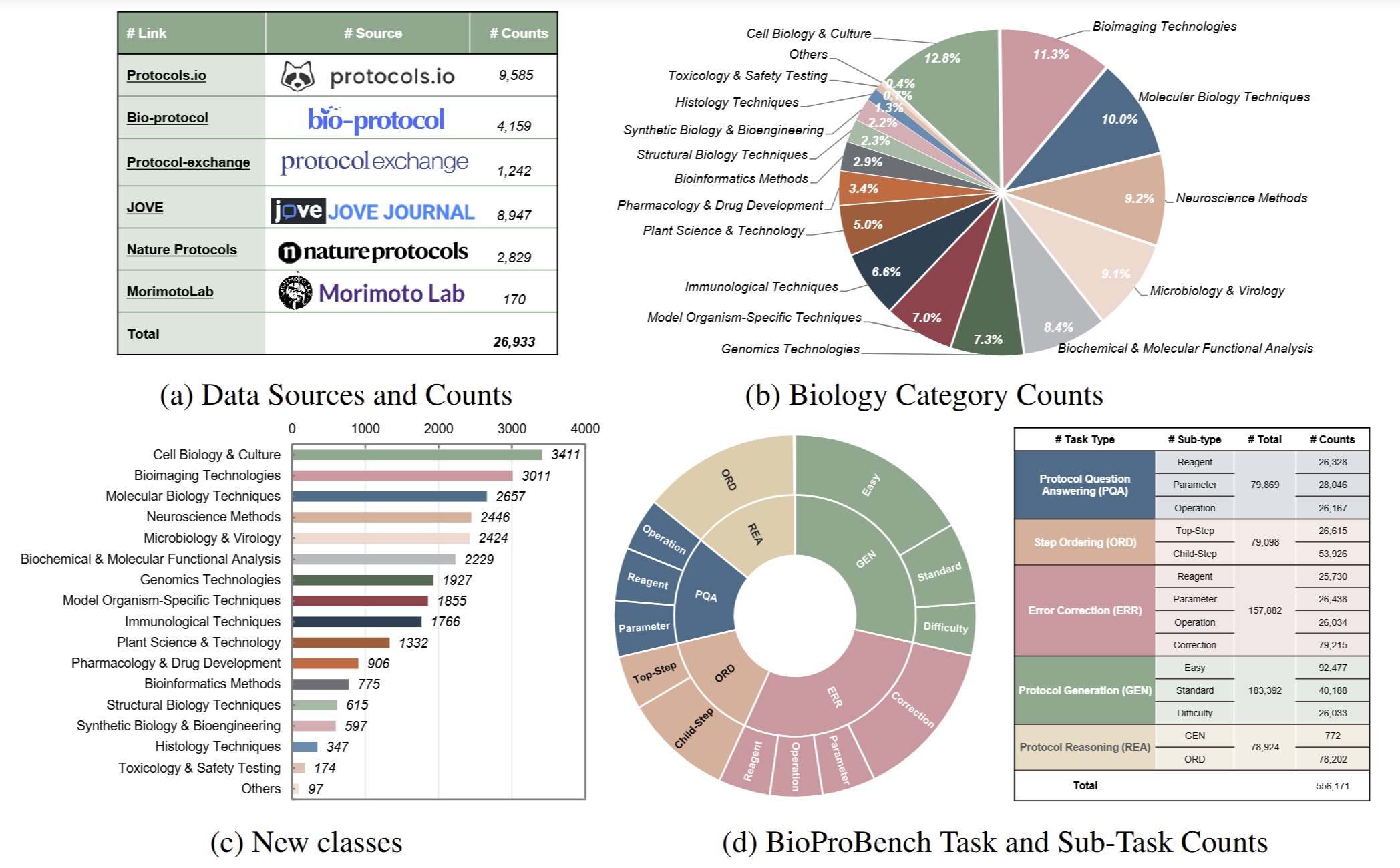
BioProBench 概览。 (a) 由 27,000 份专业撰写 protocol 构成的基础语料; (b) 基于 BioProCorpus 构建的超过 550,000 条结构化数据集,并划分为用于微调的训练集与保留测试集;以及 (c) 一个带有新颖领域指标的严格基准,用于评估流程理解能力,包括基于关键词的内容指标与基于嵌入的结构指标,从而更准确地量化程序性知识。